Introducing Sahara
Introducing a decentralized AI network with high performance, provenance, trustlessness, and privacy.


Sahara AI is the first decentralized AI network designed to empower anyone, individuals and businesses, to deploy and use personalized, autonomous AI.
Here's what sets us apart:
Proven Success & Scalable Growth: Since its inception, the Sahara team has secured multi-million revenue streams from top enterprises like Microsoft, Amazon, MIT, Snapchat, Character AI, and more. Currently serving 30+ enterprise clients with access to 200K+ AI trainers globally, Sahara is rapidly expanding and empowering participants to contribute to and benefit from the collaborative economy model.
Innovative Technology: Sahara AI is a purpose-built network with multiple layers:
- Execution Layer: A network of public and private nodes for data storage, model hosting, and multi-agent communication with high performance, privacy, and provenance. This layer is built with proprietary tech that includes decentralized LoRA, hypertuning, PKI, and personal watermark.
- Transaction Layer: This is the permissionless blockchain layer that ensures data availability and attribution, an immutable record of network transactions, trustless computation, and cross-chain interactions.
- Application Layer: Sahara is the only AI network with a natively built-in decentralized data marketplace for data collection, labeling, and access. This layer also offers toolkits for everyone to create and deploy their own knowledge agents, making AI more accessible and customizable.
- Visionary Leadership: Co-founder Professor Sean Ren, who is a leading AI expert (Ph.D. in CS from UIUC and postdoc work at Stanford), and co-founder Tyler Zhou, who is well-versed in Web3 with degrees from UC Berkeley, lead a team of global talents with experience in AI and Web3.
Strong Backing: Sahara is backed by prominent Web3 and AI investors, including Polychain Capital, Sequoia Capital, Matrix Partners, Samsung Next, and Canonical Crypto.
Why a Decentralized AI Network Is Necessary
For decades, there has been a trade-off between privacy and the benefits of data and what would become artificial intelligence. Applications like recommender systems, search, and free apps, all accumulate private data to improve their features over time. There’s always been friction between users and the platforms controlling access to online content and commerce, but now we’ve reached an inflection point.
On November 30, 2022, OpenAI released ChatGPT. All of a sudden anyone with a computer could have access to AI capable of generating usable text or code, and entire categories of employment were under threat. An early study showed an immediate impact on Upwork, the digital casual labor market, with freelance artists, writers, and developers losing wages and offers of work. Today, AI outperforms humans in fields like translation and summarization and will soon surpass them in many others.
These knowledge models were made from agglomerations of Github, Wikipedia, Reddit, and other user-created knowledge databases. We’ve all contributed to large AI models, but only a tiny fraction of us have seen a material benefit from doing so. This model won’t last much longer. As AI continues to improve, users who contribute data to centralized AI models will eventually be replaced or heavily impacted. The solution is to disintermediate the underlying infrastructure and find a way to keep proprietary data in the hands of consumers and allow them to be compensated for the use of their data. In short, we need to develop a decentralized AI infrastructure with high performance, privacy, and provenance.
Introducing the Collaborative Economy
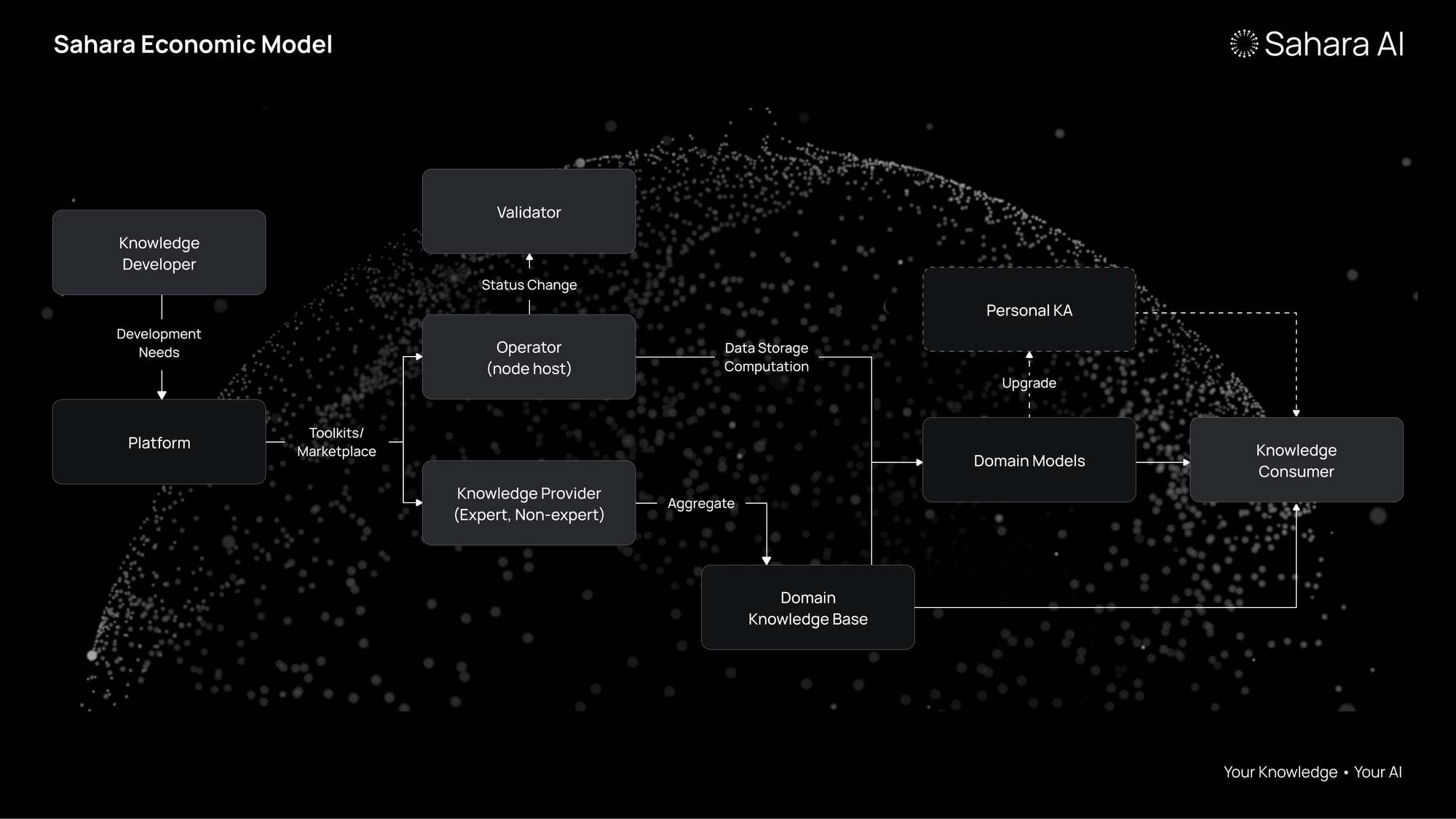
We are defining a new economic model for the Age of AI that will benefit everyone and allow anyone to participate in the AI economy. To do so, we’re building a decentralized AI network that will facilitate secure, private, ownership-preserving exchanges of data and AI models derived from user-proprietary data.
“Everyone adds a little grain of sand” – Sean Ren, Sahara CEO and co-founder.
Think of it as a self-sustaining collaborative economy that anyone, regardless of level of expertise can participate in: anyone can contribute to data collection, labeling, and training efforts. These combined efforts produce domain knowledge models, offering expertise in specific realms that can be combined with proprietary knowledge to create custom Knowledge Agents (KAs) that can be scaled up and monetized with fees flowing to everyone who had a hand in their creation.
Everyone shares in the provenance and ownership of the new economy including knowledge developers, knowledge providers, compute providers, execution node operators, validators, knowledge consumers, and many more to be explored
The Sahara Network: Infrastructure and Applications
Sahara is building the world’s best decentralized AI infrastructure and, when combined with Sahara Data (our marketplace, detailed below) can rapidly serve both user needs whether they are individuals or businesses, protecting their data, offering high performance, and ensuring their work is properly attributed and controlled throughout the network.
Here’s how it works. Sahara’s Network consists of four layers:
The Transaction Layer
Sahara Network is a purpose-built L1 blockchain for anyone, individual or business, to freely and securely deploy their personalized, autonomous AI. It provides complimentary AI access (community-built knowledge bases, training datasets, domain-specific foundational models, personalized LoRA/vault, etc) to all other blockchains.
The Transaction Layer primarily addresses data on-chain practices, transaction types, consensus mechanisms, and other aspects of executing protocols and constructing applications within the L1 blockchain. This is done to ensure ownership and provenance of data sources (e.g., data storage state), the credibility of model transactions (e.g., publication of inference results), node transactions (e.g., inter-node communication state), and efficient interaction with other blockchains. Here, we adopt a Byzantine Fault Tolerance (BFT) algorithm to achieve a finalized state, thereby constructing Sahara L1 blockchain. Tendermint’s consensus mechanism is well-suited for applications requiring high transaction throughput, quick finality, and a strong security guarantee, even in environments where some participants may act maliciously.
Specifically, Sahara’s transaction layer has the following utility:
- Data availability and attribution: All nodes on the Sahara Network have their own public keys and certificates under the public key infrastructure (PKI) to determine their access rights to specific data or model when using services. Different from transactional data, the data for AI training or inference will be stored off-chain using a decentralized storage infrastructure. Tools such as KZG commitment are used to ensure data consistency and also prevent tampering by malicious nodes. Meanwhile, training data contributed by users will carry the contributor’s DID information to ensure provenance of the model. This key information is included in Sahara chain’s distributed ledger which is readily available for verification, analysis and transaction validation.
- Immutable record for network transaction: Important user operation transactions and attributes (e.g., labeling task acceptance rate, labeling speed of a task, data or model access) that have significant economic value for Sahara will be recorded on-chain as an immutable record of Sahara users. These user-centric, immutable data will be a critically important data source for constructing Sahara’s on-chain reputation system. Meanwhile, data availability-related transactions, e.g., proofs that show the computation logic are trustworthy, are recorded on-chain to ensure the integrity of data and model computation.
- Trustless computation: To ensure that Sahara nodes maintain integrity and high performance during model training and inference, we decompose the workflow into a series of computational decisions corresponding to different state transitions. For these transitional states, we establish checkpoints and employ fraud proofs to detect and validate the absence of malicious behavior. As training occurs offline, we use optimistic rollup (OP) proofs to affirm the credibility of the training and the model. Then, consensus mechanisms are utilized to ensure the trustworthiness of inferences. This helps prevent nodes engaged in model computation activities from malicious manipulation of computational processes.
- Cross-chain interaction: We adopt inter-blockchain communication (IBC) protocol to ensure secure exchange of data and tokens across different sovereign blockchains. IBC works by establishing a connection between two blockchains, followed by creating a communication channel within that connection. The protocol then manages packet forwarding between the chains. Building on IBC, Sahara network enables cross-chain interactions such as data sharing, model deployment, access to Sahara’s decentralized data marketplace, incentive alignment, and enhanced privacy. By implementing a system that supports such robust cross-chain functionalities, the models can operate more fluidly and efficiently, leading to a more interconnected and intelligent blockchain ecosystem.
The Execution Layer
Built on top of the Transaction Layer is the Execution Layer, which supports the deployment of AI, essentially data, models, and KAs, while maintaining four key properties: high performance, decentralization, privacy, and provenance (trace of ownership and attribution — an influence function for data attribution). Here, individual nodes secure data storage, transfer data between nodes and facilitate applications like Sahara Data and KAs (Knowledge Agents). The Execution Layer maintains three key properties and builds on a fourth, decentralization, maintained by the Transaction Layer:
High Performance is maintained through decentralized Low-Rank Adoption of LLM models (LoRA) for hypertuning models. There’s end-to-end reward maximization, allowing customization and evolution; secure data handling and dynamic data management, and privatized parameter handling with personalized adaptation and plug-and-play parameters.
Privacy is maintained through the use of privacy-preserving training and inference. User personal data can be securely stored in private nodes or decentralized public nodes, and trained using cryptographic methods.
Provenance consists of proof of ownership: i.e. digital water-marking and a commitment scheme, and data storage and access: a public key infrastructure, and AES encryption. Data transportation is secured using private computing and homomorphic encryption.
Without an execution layer, the provenance and attribution of personal knowledge capital would not work. With an Application Layer, we can democratize the current AI economy and push for a collaborative economy.
The Application Layer
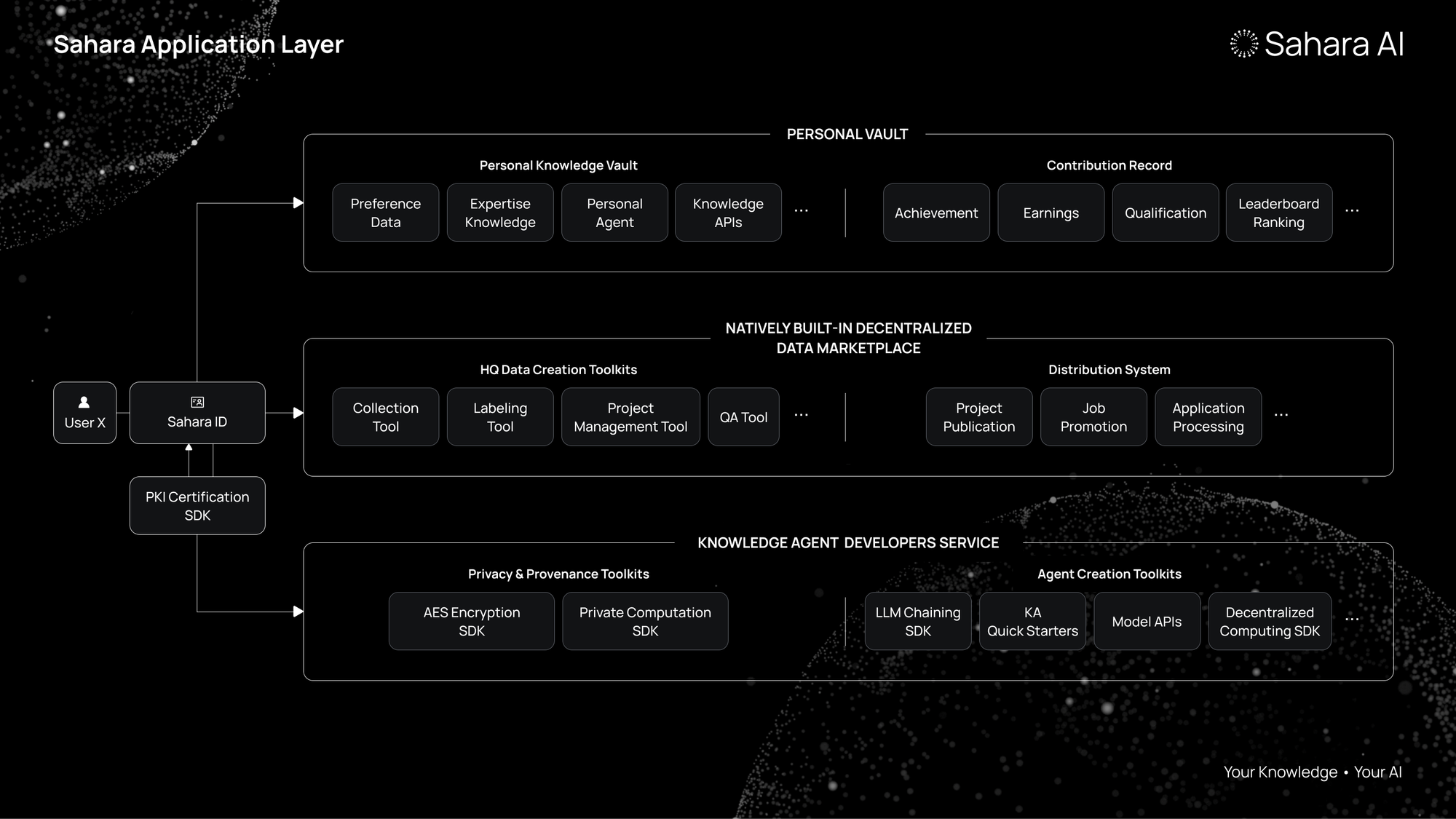
The Application Layer sits on top of the execution layer and is where the proverbial magic happens. There are several systems, including a natively built-in data marketplace for data collection, labeling, and accessing that NO OTHER AI network in web3 has today.
Sahara ID: Users belong to Sahara’s reputation system, which provides both provenance and security in the form of exclusive access to their Personal Knowledge Vault, and their Contribution Record which tallies their contributions to the network in the form of achievements, earnings, and qualifications.
Sahara Data (Sahara Data Marketplace): Sahara’s natively built-in decentralized data marketplace is already being used by enterprise clients like MIT, Microsoft, USC, the Motherson Group, and many others to help train their AI models. The marketplace consists of a data toolkit (collection, labeling, QA, etc.), a distribution engine, and a project management tool. We will extend data ops tools for all users, individuals, or businesses, to access.
Sahara Knowledge Agents: Our Knowledge Agents (KAs) are custom AI programs that operate semi-autonomously. They’re built on large fundamental models but fine-tuned with proprietary data that is kept private and secure. Users will have access to Privacy and Provenance Toolkits and Knowledge Agent development toolkits, making it easy for developers to create and monetize their KAs.
Knowledge Rebasing: On Sahara, not only can people branch their own AI, they also have the chance to collaborate on evolving AI through a shared ecosystem. Our model-merging toolkits and Knowledge Agent networks can unify multiple decentralized AIs and knowledge. By using these advanced tools, users can create a more comprehensive and interconnected AI experience, fostering an environment where collective intelligence thrives.
The Economic Layer
Describes the activity created by participants on the Sahara Network as guided by the incentive mechanisms and put in place by users and the network. Tokens and gamification provide basic value exchange and fee payments, enabling the Collaborative Economy.
Over the coming months, we'll continue to roll out components of our decentralized AI network. This includes Sahara Knowledge Vaults as well as no-code development kits for personal Knowledge Agents and communications between them (Sahara Knowledge Agents Personal and Sahara Protocol). Sahara is building a network where every participant has monetization opportunities, whether it’s collecting/labeling to earn, contributing one’s expertise to build a valuable vault of domain knowledge, selling access to personalized Knowledge Agents, operating nodes, validating transactions, providing compute, or anything else that adds value to the network.
Why We’re The Ones to Do It
Sahara was founded in May 2023 by a team of experts from the AI and web3 industries, and led by Professor Sean Ren and Tyler Zhou. Having earned accolades including Samsung AI Researcher of the Year, MIT TR Innovator under 35, and Forbes 30 Under 30, Sean is a Professor at USC. He has contributed significantly to AI research and innovation. Additionally, Tyler has extensive experience in the blockchain industry as the previous Investment Director at Binance Labs.
We have the best AI talent, with more than 30 contributors working on Sahara. Our culture is intellectually and geographically diverse, pragmatic, research-driven, and dedicated to delivering the new Age of AI.
Why We’re Called Sahara
Data science has coined many overarching metaphors: there’s digital black gold or the idea of a digital ocean, but to us, the image that called to us the most was that of the Sahara Desert. There’s an obvious resonance between a grain of sand and silicon dioxide in a transistor. We also like the way that an individual grain of sand could represent a tiny nugget of human knowledge and that patterns in the sand, the dunes, the ripples, and irregularities and encrustations could represent the multidimensional complexity of an artificially intelligent model, as could oases or the desert fauna, not to mention the promise of lost cities and hidden dangers and opportunities and the great unknown represented by the world’s largest desert.
Our Seed Round

We are excited to announce our $6 million seed funding round from last September. The round was led by Polychain Capital with participation from Sequoia Capital, Samsung Next, Matrix Partners, Motherson Group, dao5, Geekcartel, Canonical Crypto, Nomad Capital, Dispersion Capital, Alumni Ventures, Tangent Ventures, Coho Deeptech, and many more.
We plan to use the newly acquired funds to expand our team and enhance our portfolio of AI and blockchain-enabled products. Throughout the year, besides Sahara KA and Data, the network will grow to encompass Sahara Vault, Sahara ID, and Sahara Network for all individuals and businesses to navigate freely in the Sahara ecosystem.
Find Out More
We hope we’ve whet your appetite for more information about the Sahara Network. Follow us on Twitter here for more updates coming soon.